
Building a RAG layer for local LLMs for Skyrim knowledge
Combining existing opensource software, I made a RAG layer for embedding Skyrim Knowledge on local LLMs.
Large Language Models (LLMs) have rapidly gained popularity since the launch of ChatGPT back in 2022. Following its launch, the open source community have been at an arms race to build open models with matching capabilities, making this technology more accessible for private, personal and research use.
In my experience, they succeed. Several open source software are now available, allowing your machine to run locally essentially the same technologies in a few commands. Personally, my setup uses Ollama for downloading, running and managing opensource models and Open WebUI, which does a wonderful job providing an interactive web interface for interacting with the models.
Motivation
Still, the biggest challenge for realizing our "LLM-at-home" dream comes from the massive parameter size required to match the results that a ChatGPT or a Gemini model displays. Simply put, customer GPUs have at most 24gb, enough to play with up to 32B parameter models capable of writing code, summarizing text or coming up with stories, but far from the massive size of those proprietary model that enable them to retain specific knowledge from different domains, like those found in games and media.
A common solution for this is the usage of Retrieve Augmented Generation (RAG). Simply put, RAG involves retrieving relevant information from documents and providing it to the model alongside the user's query, aiding the model with the knowledge it requires to correctly answer the question. As a result, the LLM doesn't need to store this knowledge on its parameters, but rather, just be able to synthesize and summarize information -- something a 14B+ model are more than capable of doing.
Goals
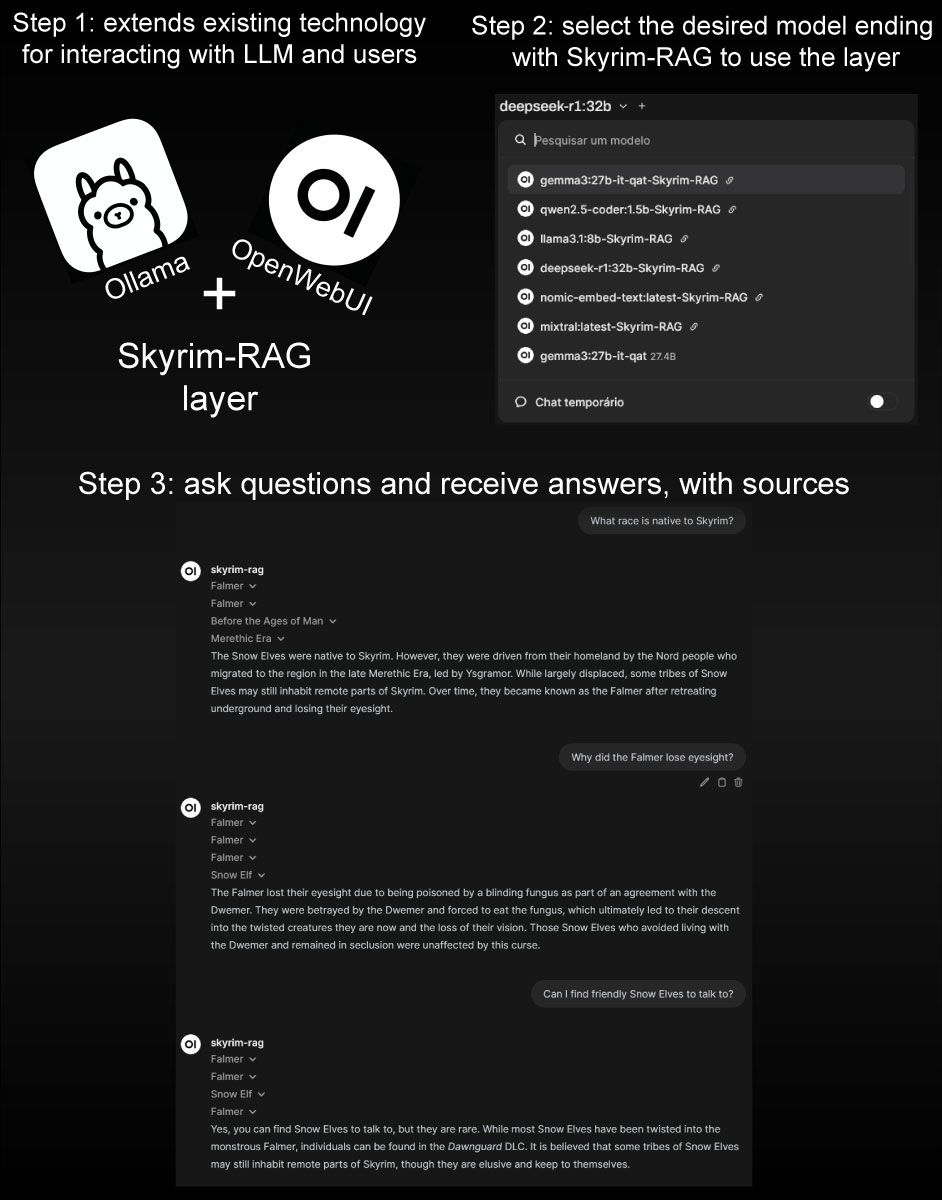
Motivated by this, I set up the goal of building a local RAG system for enhancing specific knowledge for my local Gemma27B model. To this end, I chose to implement a Skyrim RAG system, since the game has vast scope, and a iconic status, coupled with the fact it's finite knowledge is easily available in the internet: it's Fandom page . Furthermore, I found a dump of the database is easily downloadable from their statistics page .
More importantly than simply studying and exploring the libraries and technologies involved, I wanted to explore how to use them effectively using well established tools. There's a significant difference between following a tutorial and building a self-contained, end-to-end product. Therefore, I established the following goals:
- Should be entirely local, using existing opensource technology (no reinventing the wheel)
- Should be compatible with existing UIs, specifically, Open WebUI (it's what I use)
- Should provide the retrieved documents that was used for generating the response (to check if it's not hallucinating)
Available as a Docker image
If you want to simply test the RAG layer, it's available as a docker image that you can pull directly from Docker Hub, just run the following commands to install it and configure within your Open WebUI as below.
Available on GitHub
The project is available in GitHub , with comprehensive comments.
How it works
Technologies used
The project leverages the following python libraries:
- LangChain and LangGraph: For constructing and managing the RAG pipeline.
- ChromaDB: For serving as the vector database to store and retrieve embeddings associated with Skyrim's Wiki content.
- Flask: Used to create the API that interfaces with the RAG system, allowing seamless integration with other systems that implements the Open WebUI.
Creating the vector store
Creating the vector store is a one-time task and has been fully implemented in the create_vector_store.ipynb notebook. To run it, you will need the XML dump of Skyrim's Wiki database. You can download it directly from Skyrim Fandom's XML dump (at the end of the page). Once downloaded, follow the instructions provided in the notebook to construct the database.
ChromaDB is used as the vector database for this project, leveraging the nomic-embed-text embedding model to generate
dense vector representations of the Skyrim Wiki content. Additional details on how this is implemented are available in
the create_vector_store.ipynb notebook.
RAG-based pipeline
We use LangChain and LangGraph to interact with Ollama models and manage the RAG system's workflow seamlessly. The pipeline works like this:
Using with Open WebUI
Configuring Open WebUI to use the software
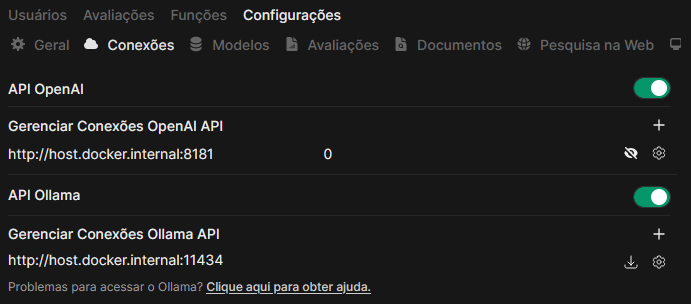
To use the software, navigate to the connection settings of your Open WebUI instance. Enable the usage of the OpenAI API
and register a new API using the URL and port you configured. For instance, if your Open WebUI is running on a Docker
container and the RAG system is accessible on your local machine
with port 8181, you'd register the API with the following URL:
Interacting with the models
Next time Open WebUI reloads model list, for each model on your Ollama instance, a new option ending with "Skyrim-RAG" will appear. Simply select the model you want to generate the answer ending with "Skyrim-RAG" to use it with our RAG layer. Similarly, chose the option that doesn't end with Skyrim-RAG to use the base model.
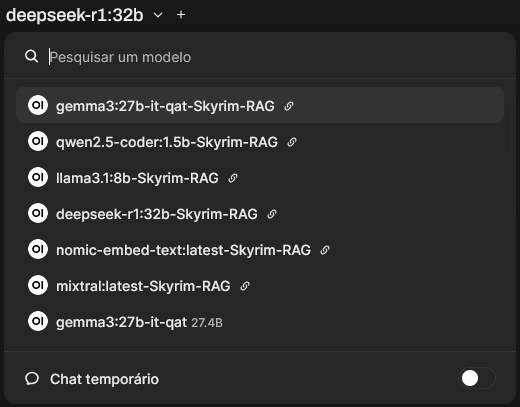
My experience testing a few models
On the topic of which model to choose, I personally only use it with Gemma3:27B (QAT). It's a very competent model which behaves very well for following instructions. DeepSeek-R1:32B also behaves well, but it's reasoning nature makes it prone to overthinking and answers take much longer unnecessarily. I found Llama3.1:8B to be poor in following instructions, and often suggested poor search terms, which negatively impacts the accuracy of the answers.
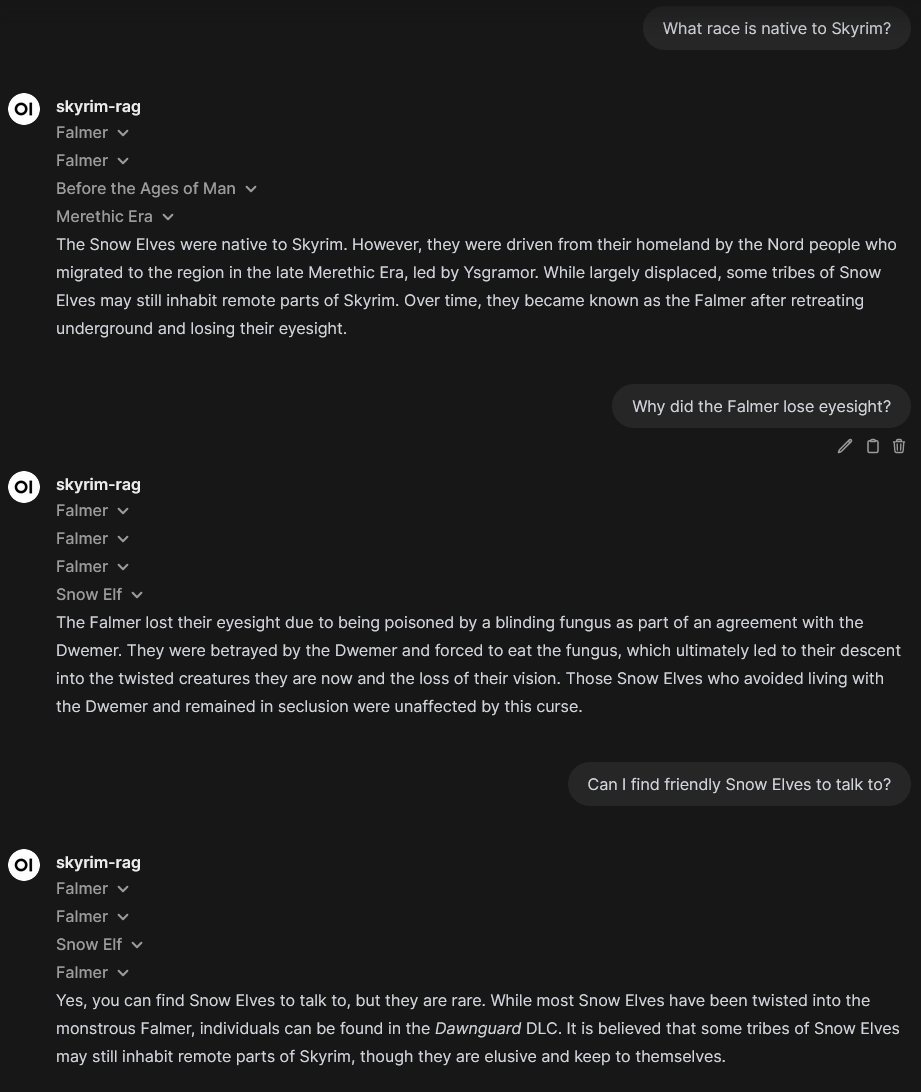
Question-answering with the software
After sending a question, the model will use the LLM to propose search terms and use those to retrieve relevant documents. Once the documents are retrieved, it will send them to the UI, where the user can explore them. After that, it will start to stream the LLM answer as normal. In practice, interacting with the model looks like this:
| Example 1 | Example 2 |
|---|---|
 | 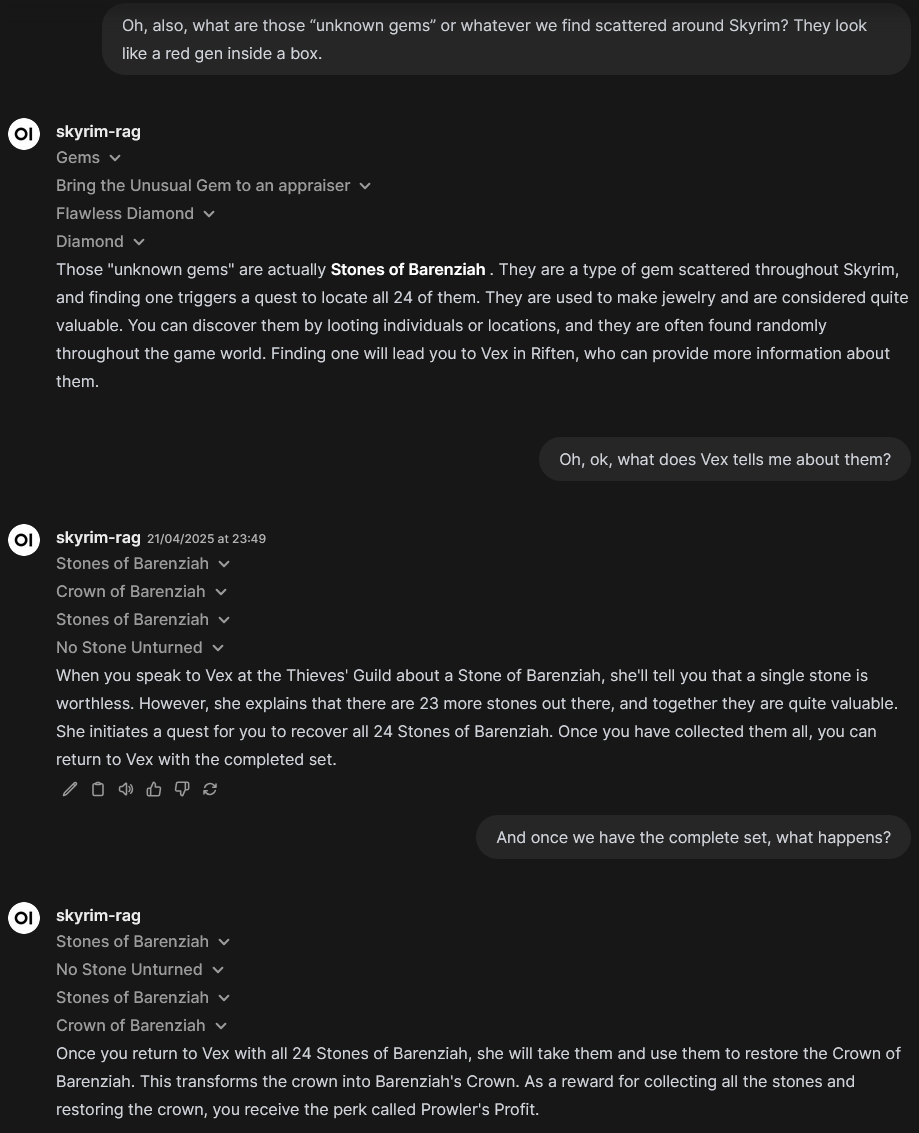 |
Concluding remarks
Overall, it was a fun project for studying a new technology and embedding it in a practical and user-friendly application. The software fits perfectly in my current stack, being able to be started as a docker container when needed, and only used based on the selected model on the Open WebUI interface. The end result is indistinguishable from a normal interaction with a classic LLM, save for the document snippets that are added into the interface when answering.
Skyrim as a subject was chosen because it was an interesting application. However, future work will focus on applying this software to a more practical and useful setting, using a real-world knowledge database. An initial idea is to build a research paper repository, using the same approach studied in this project for question-answering from research paper content. To this end, the Flask API could be extended to include a UI to allow for the upload of PDF documents, and automatically extract, index and store the information from them.